

MSA 환경에서는 네트워크 장애, 리소스 부족, Pod 실패와 같은 다양한 오류가 일어났을 시에 원인 지점을 빠르게 찾아내는 기술력이 필수적이다.
의도적인 장애나 혼란을 주입해 시스템의 취약점을 찾아내고, 장애가 발생하더라도 안정적으로 동작할 수 있도록 개선할 수 있는 Chaos engineering 오픈 소스 중 Chaos mesh에 대해 다룬다.
Chaos Mesh
chaos mesh는, 마치 스위스 군용 칼처럼 다양한 장애 상황을 제어된 방식으로 미리 시뮬레이션할 수 있다. Kubernetes 기반 MSA 환경에서 복잡한 장애 상황을 손쉽게 재현하며, 클러스터에서 안정적으로 실험을 수행한다. Kubernetes와의 완벽한 통합 덕분에 실시간으로 다양한 장애를 주입하고 분석할 수 있다. 다양한 장애 유형(네트워크, 리소스, 시스템 수준의 문제)을 주입해 시스템의 취약점을 사전에 발견하고, 복구 및 개선 작업을 위한 데이터를 제공한다. 또한, 오픈소스 특성상 비용 효율적이고, 다양한 오픈소스 커뮤니티의 지원을 받을 수 있다는 점에서도 강점이 있다. 이러한 이유로 Chaos Mesh를 선정했다.
Chaos Mesh 구성과 동작 방식
Chaos Mesh는 Kubernetes CRD 기반의 Chaos Engineering 도구로, 시스템에 제어된 방식으로 다양한 장애를 시뮬레이션하여 복원력을 테스트하는 역할을 수행하며, Chaos Dashboard, Chaos Controller Manager, Chaos Daemon 세 가지 핵심 구성 요소로 이루어져 있다.
Chaos Mesh구성
- Chaos Dashboard: 사용자에게 시각적 인터페이스를 제공하며, Chaos 실험을 설정하고 모니터링할 수 있는 웹 대시보드. RBAC(Role-Based Access Control)에 기반한 권한 관리가 가능하다.
- Chaos Controller Manager: Chaos Mesh의 핵심 제어 컴포넌트로, 다양한 실험을 스케줄링하고 관리한다. Kubernetes API 서버와 통신하여 이벤트를 수신하고, CRD(사용자 정의 리소스)를 기반으로 실험을 실행한다.
- Chaos Daemon: 장애 실험을 실제로 실행하는 구성 요소로, DaemonSet 방식으로 배포되며, 노드의 리소스 및 네임스페이스를 제어한다. 이를 통해 특정 네트워크 장치나 CPU, 메모리 등의 자원을 혼란시키는 방식으로 실험을 수행한다.
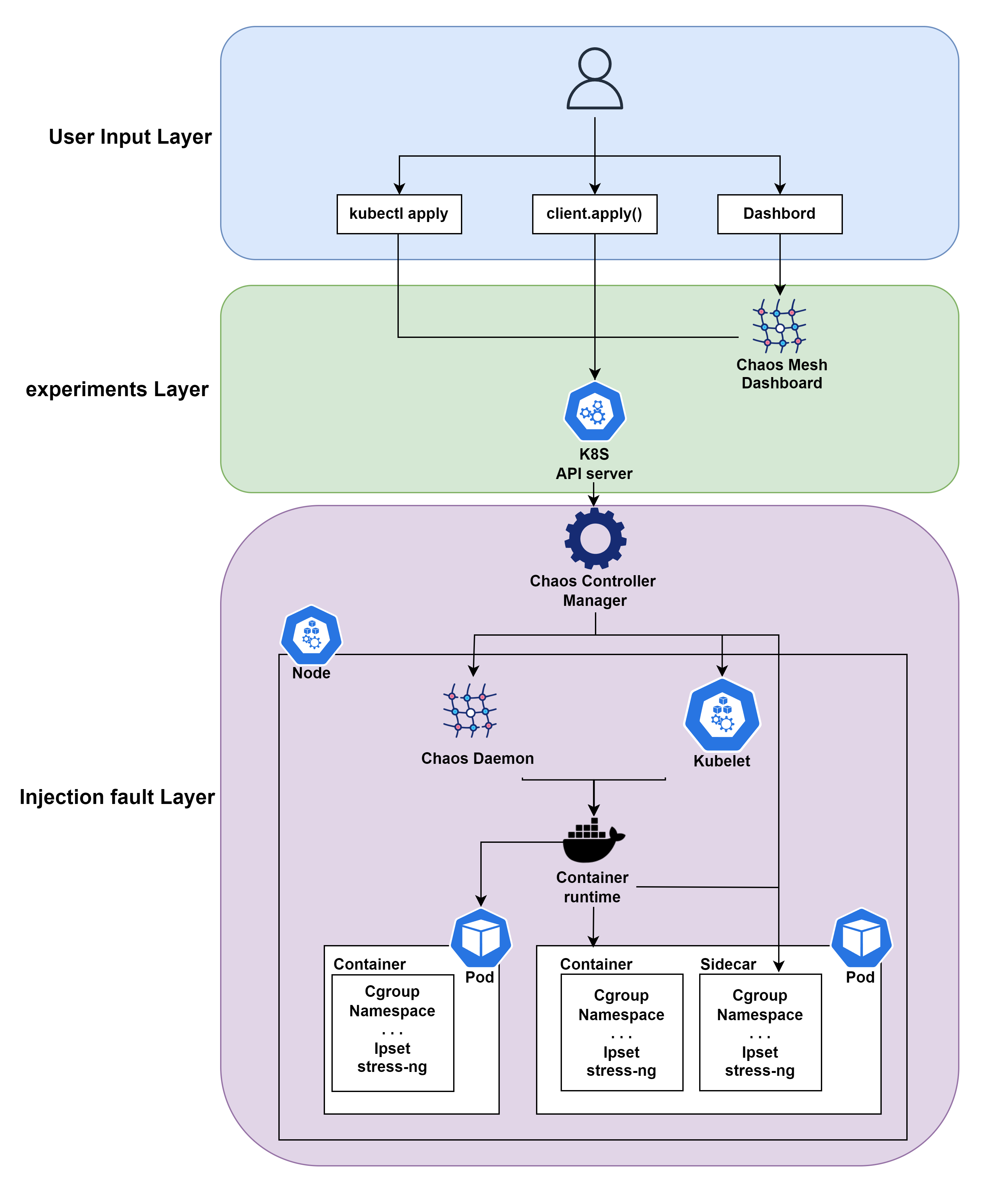
Chaos Mesh의 아키텍처는 3 부분으로 나눌 수 있으며 역할에 따라 임의로 이름을 붙여주었다.
- user input Layer : 사용자는 kubectl cli, client.apply(), dashboard ui 3가지 방식으로 input을 줄 수 있다. 3가지 방식 모두 chaos mesh의 Controller Manager와 직접적으로 상호작용하는 것이 아니라 Network Chaos, Stress Chaos 등 쿠버네티스의 리소스를 변경한다
- experiments Layer : 쿠버네티스의 api server가 리소스의 변경사항을 모니터링하고 스케쥴링하는 레이어이다. api server는 input Layer에서 입력된 리소스 변경을 감지하고 Chaos Controller Manager로 변경 사항을 전달한다.
- Injection fault Layer : 본격적으로 장애를 주입하는 레이어이다. Chaos Daemon은 Chaos Controller Management의 명령을 수락하고 대상(pod, node 등)을 해킹하여 오류를 주입한다. 특정 오류에는 CPU 스트레스, 네트워크 지연, 특정 pod 접근 차단이나 실패처리 등 다양한 기능이 있으며, 예를 들면 CPU 또는 메모리 리소스를 선점하기 위해 stress-ng 프로세스를 실행하는것이 있다.
설치 및 테스트
Helm사용하여 Chaos Mesh 설치
코드를 활용한 gitops에 유리하도록 Helm을 이용해 설치했다.
# add chaos-mesh chart
$ helm repo add chaos-mesh https://charts.chaos-mesh.org
# create namespace chaos-mesh
$ kubectl create ns chaos-mesh
# install choas-mesh version-2.6.3
$ helm install chaos-mesh chaos-mesh/chaos-mesh -n=chaos-mesh --version 2.6.3
# check resource
$ kubectl get deployments.apps -n chaos-mesh
NAME READY UP-TO-DATE AVAILABLE AGE
chaos-controller-manager 3/3 3 3 39h
chaos-dashboard 1/1 1 1 39h
chaos-dns-server 1/1 1 1 39h
Dashboard 접근
port-forward, ingress 등의 방식으로 dashboard에 접근하면 ui 방식으로 Chaos-mesh를 사용할 수 있다.


cluster scoped 버튼을 클릭하면 클러스터 전체에서 통하는 clusterrole 생성 manifest 파일을 작성해준다.
Cluster scoped
kind: ServiceAccount
apiVersion: v1
metadata:
namespace: default
name: account-cluster-viewer-ucken
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: role-cluster-viewer-<랜덤 값>
rules:
- apiGroups: [""]
resources: ["pods", "namespaces"]
verbs: ["get", "watch", "list"]
- apiGroups: ["chaos-mesh.org"]
resources: [ "*" ]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: bind-cluster-viewer-<랜덤 값>
subjects:
- kind: ServiceAccount
name: account-cluster-viewer-<랜덤 값>
namespace: default
roleRef:
kind: ClusterRole
name: role-cluster-viewer-ucken
apiGroup: rbac.authorization.k8s.io
cluster scoped 버튼을 해제하면 특정 네임스페이스에 대한 role 리소스에 대한 manifest 파일을 작성해준다.
kind: ServiceAccount
apiVersion: v1
metadata:
namespace: chaos-mesh
name: account-chaos-mesh-manager-<랜덤 값>
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: chaos-mesh
name: role-chaos-mesh-manager-<랜덤 값>
rules:
- apiGroups: [""]
resources: ["pods", "namespaces"]
verbs: ["get", "watch", "list"]
- apiGroups: ["chaos-mesh.org"]
resources: [ "*" ]
verbs: ["get", "list", "watch", "create", "delete", "patch", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: bind-chaos-mesh-manager-<랜덤 값>
namespace: chaos-mesh
subjects:
- kind: ServiceAccount
name: account-chaos-mesh-manager-<랜덤 값>
namespace: chaos-mesh
roleRef:
kind: Role
name: role-chaos-mesh-manager-<랜덤 값>
apiGroup: rbac.authorization.k8s.io
파일을 작성하고, 쿠버네티스에 apply하면 토큰 생성을 위한 각 리소스가 배포된다.
$ kubectl apply -f rbac.yaml
$ kubectl create token account-chaos-mesh-manager-<랜덤 값>
UI 소개
Dashboard 메인 페이지

kubectl create token 명령으로 ServiceAccount에 대한 token 값을 생성 후 dashboard에 입력해서 로그인해준다.
메인 페이지에는 왼쪽부터 각 서비스로 연결되는 버튼이 있으며, 현재 생성된 Experiments, Schedules, Workflows 수와 더불어 최근 이벤트를 확인할 수 있다.
Experiments

Experiments 탭에서는 쿠버네티스, 호스트에 개별적으로 장애를 주입할 수 있는 시나리오를 버튼과 텍스트 필드 형식으로 손쉽게 작성할 수 있다.
기본적으로 제공하는 장애 주입 방법은 다음과 같다
kubernetes
- AWS/GCP Fault
- Stop EC2/node : 인스턴스 중지
- Restart EC2 / Reset node : 인스턴스 재시작
- Detach volume / Loss disk : 인스턴스에서 스토리지 볼륨을 제거
- Block Fault
- delay : 블록 장치의 대기 시간 delay
- DNS Fault
- random : 작성한 도메인에 대한 접속 시 임의의 IP 반환
- errer : 작성한 도메인에 대한 접속시 오류 반환
- IO Injection
- latency : 파일 시스템 호출을 지연
- fault : 파일 시스템 호출에 대한 오류를 반환
- attrOverride : 파일 속성을 수정
- HTTP Fault
- abort : 연결을 중단
- delay : 요청이나 응답에 지연 시간을 주입
- replace : HTTP 요청 또는 응답 메시지의 일부 내용을 대체
- patch : HTTP 요청 또는 응답 메시지에 추가 콘텐츠를 추가
- Kernel Fault
- KernelChaos를 사용하여 Linux 커널 오류를 시뮬레이션 지정된 커널 경로에 I/O 기반 또는 메모리 기반 오류를 주입
- 주입 대상을 하나 이상의 Pod로 설정할 수 있지만, 모든 Pod가 동일한 커널을 공유하기 때문에 호스트의 다른 Pod 성능에 영향
- 기본적으로 비활성화 되는 기능이며 프로덕션 환경에서 사용은 위험
- Network Attack
- Partition: 네트워크 연결 해제 및 분할
- Net Emulation: 높은 지연, 높은 패킷 손실률, 패킷 재정렬
- Bandwidth: 노드 간 통신 대역폭을 제한
- Pod Fault
- Pod Failure : Pod에 오류를 주입하여 일정 시간 동안 Pod를 사용할 수 없게 만듦
- Pod Kill : Pod 종료, Pod를 성공적으로 다시 시작할 수 있도록 하려면 ReplicaSet 등을 사전에 구성
- Container Kill : 대상 Pod에 있는 지정된 컨테이너를 종료
- Stress Test
- CPU, Memory 등에 대한 Stress Test
- Clock Skew
- 시간 오프셋 시나리오를 시뮬레이션
- JVM Fault
- 사용자 정의 예외 발생
- 가비지 수집 트리거
- 메서드 대기 시간 증가
- 메서드의 반환 값 수정
- Byteman 구성 파일을 설정하여 오류 트리거
- JVM 압력 증가
장애 주입 시

Dashboard에서 장애 주입시 위와 같이 이벤트가 실행중인 task, 실제 쿠버네티스 환경에서 사용 가능한
manifest 코드도 확인할 수 있다.
Schedules

Events

Archives

Settings
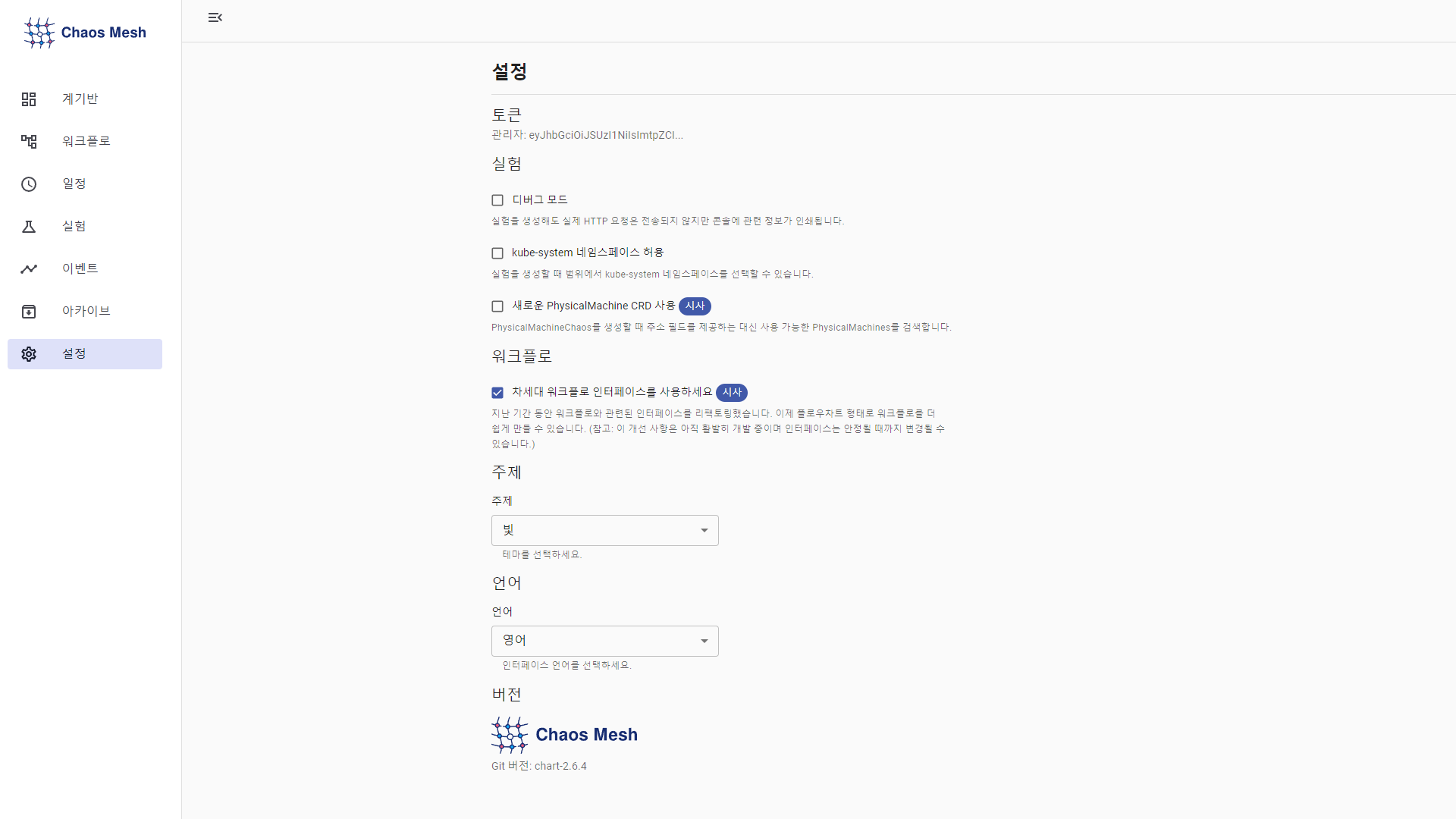
Experiments
- Debug mode : 실험을 생성해도 실제 HTTP 요청은 전송되지 않지만 콘솔에 관련 정보가 인쇄
- Allow kube-system namespace : 실험 시 kube-system 네임스페이스 선택 가능
- Use new PhysicalMachine CRD : PhysicalMachineChaos를 생성할 때 주소 필드를 제공하는 대신 사용 가능한 PhysicalMachines를 검색
Workflows
- Use the next generation of workflow interface
- 리팩토링 된 Workflows 인터페이스 사용가능
장애 주입 테스트
chaos mesh 대시보드와 k8s 환경에서 각각 테스트 해보았다.
Dashboard

- Namespace : bookshop
- Mode : Fixed Percent
- Name : pod kill 20%
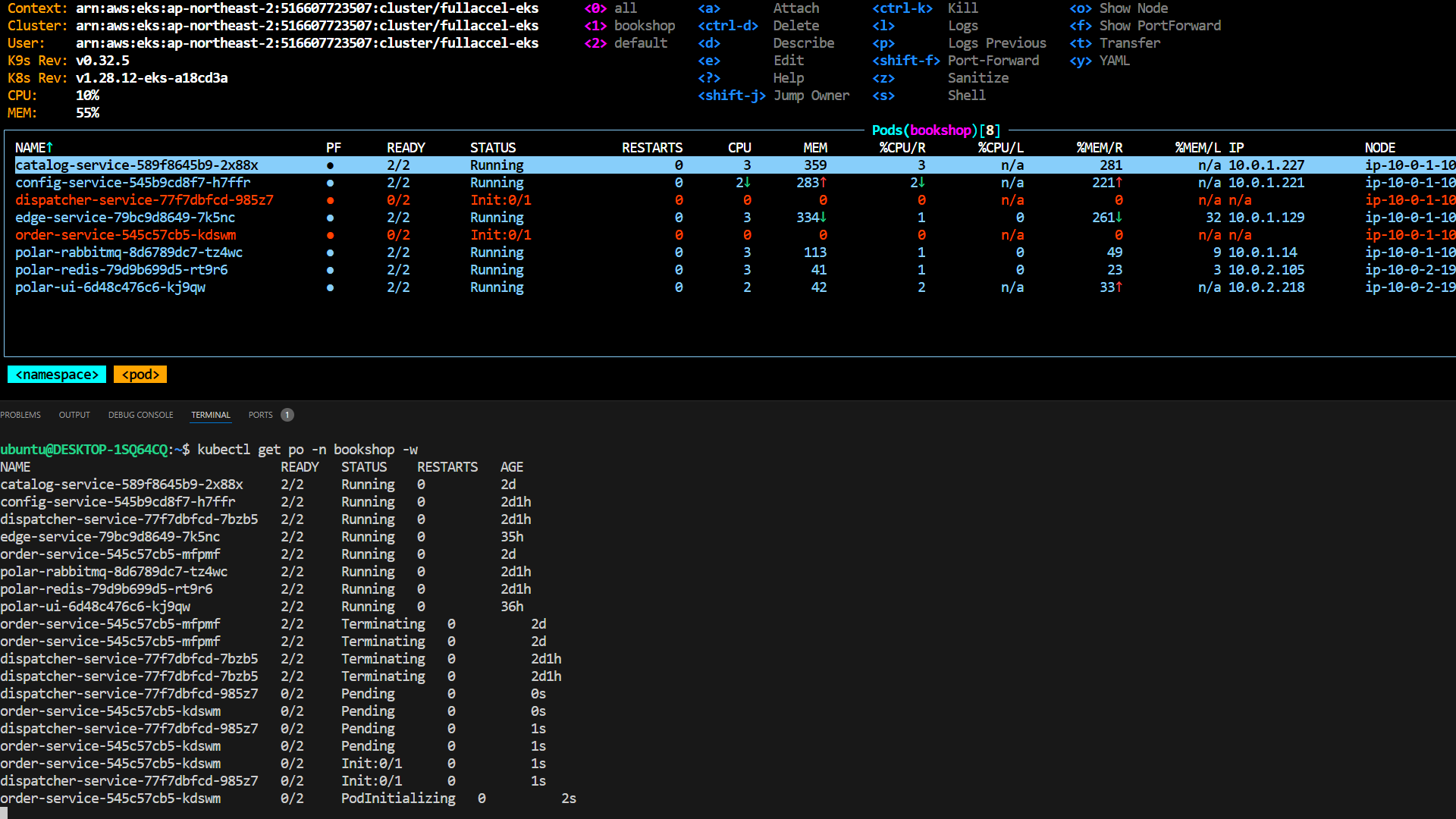

Kubernetes
k8s 환경에서 yaml파일을 작성해 장애 주입 테스트
StressChaos
apiVersion: chaos-mesh.org/v1alpha1
kind: StressChaos
metadata:
name: stress-cpu-80
namespace: chaos-mesh
spec:
mode: one
selector:
nodeSelectors:
kubernetes.io/hostname: <대상 노드>
stressors:
cpu:
workers: 2
load: 50
duration: "180s"쿠버네티스에 CPU에 Stress를 주입하는 manifest 파일이다.
작성한 파일을 배포하면, StressChaos 리소스가 생성되며 Stress Test가 시작된다.

NetworkChaos
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: network-denie
namespace: chaos-mesh
spec:
action: partition
mode: all
selector:
namespaces:
- bookshop
labelSelectors:
'app': 'edge-service'
direction: to
target:
mode: all
selector:
namespaces:
- bookshop
labelSelectors:
'app': 'polar-ui'사용자가 full-accel.com이라는 도메인으로 접속할 시에 연결되는 edge-service와 polar-ui간의 접속을 NetworkChaos 리소스를 통해 차단했다.

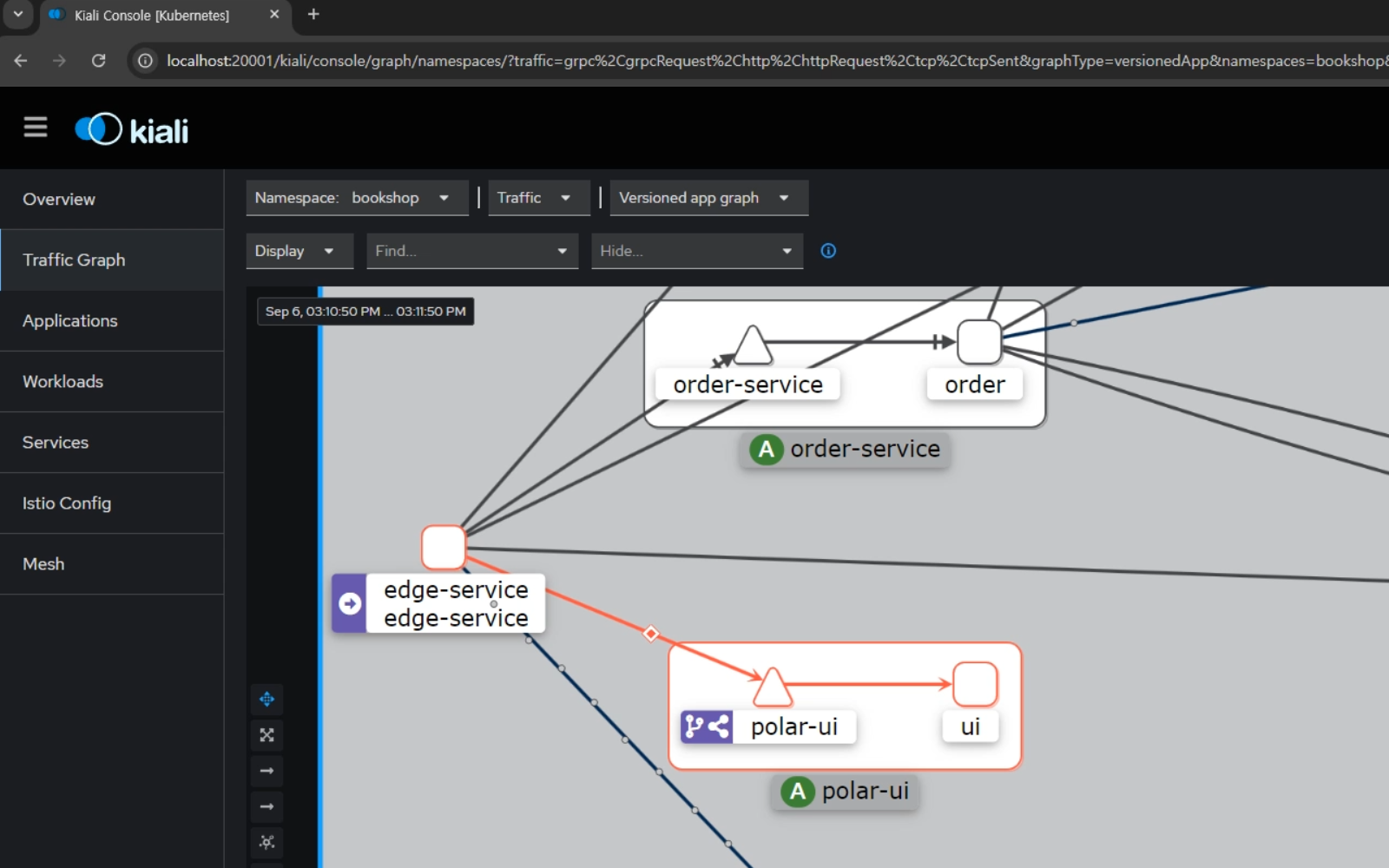
Chaos engineering 플랫폼 중 하나인 Chaos mesh를 사용한 장애 주입 테스트를 진행했다. 테스트 환경에서는 Pod가 바로 재시작되고, Chaos 리소스 삭제 시 서비스가 바로 정상으로 돌아왔다.
의도된 장애 주입이기에 빠른 추적이 가능했지만, 프로덕션 환경에서는 Pod가 바로 생성된다는 보장이 없고, 서비스에 따라 완전한 복구까지의 소요 시간이 상이할 수 있다. 바로 생성된다고해도 running상태까지의 소요 시간도 서비스별로 상이하다. 이를 고려하여 Manifest 파일에서 여러 개의 replica를 설정해 각각 여러 노드에 분산 배포하는 등 안정성을 높이는 것이 중요하다.
Chaos Mesh 시뮬레이션을 활용한 분석
테스트 결과, 복잡한 MSA 환경에서 네트워크 장애나 서비스 장애가 발생할 때 빠르게 대응하는 것이 매우 중요함을 알 수 있었다. Chaos Mesh를 통해 이러한 장애 상황을 미리 시뮬레이션하여 문제를 사전에 파악할 수 있다는 점은 큰 장점이다. 또한, 장애 발생 시 빠른 추적을 가능하게 하기 위해 Observability(관찰성) 도구들을 미리 구축하는 것이 효과적이었다. Prometheus, Grafana, Jaeger, kiali와 같은 오픈소스 도구를 사용하여 실시간으로 시스템 상태를 모니터링하고 장애 원인을 추적함으로써, 문제를 빠르게 진단하고 대응할 수 있는 준비가 되어 있음을 확인했다.
결국, Chaos Mesh와 같은 도구를 활용한 사전 테스트는 시스템의 복원력과 신뢰성을 강화하는 데 필수적이며, 이를 통해 장애 발생 시 대응 시간을 최소화하고 프로덕션 환경에서의 안정성을 높일 수 있다.